消息队列的特性
卡夫卡(Kafka)作为消息队列的一种,拥有异步、削峰、解耦三种特性,并依靠这些特性,他经常在搜索、直播、订单和支付服务。
- **异步:**不同于同步通信的需要等待接收方响应,异步通信的发送方在发送消息到消息队列后,不等待接收方响应,而是继续进行其他操作。接收方仅需要从消息队列中拉取消息即可。 异步操作减少了流程长度,提高消息的吞吐量和效率。
- **削峰:**对于突发的消息高峰,消息队列起到了存储请求的作用,使后台能以稳定的速率处理消息,从而减少了服务器的高峰负担,提高系统的稳定性。
- 解耦:解耦合即降低各个组件之间的依赖。使用消息队列,发送者和接收者各种把自己的消息发送给消息队列,从而实现解耦,方便各自开发部署,避免一方接口发生错误而影响多方,实现错误隔离。
卡夫卡的基本概念
- **逻辑队列(Topic):**可以建立不同的逻辑队列,存储于物理集群中。
- **物理集群(Cluster):**可建立多个逻辑队列。
- **生产者(Producer):**发送消息到逻辑队列。
- **消费者(Consumer)&消费者组(Consumer Group):**消费逻辑队列内的消息,各个消费者组互不干扰。
- **Offset:**记录消息在有序序列Partition中的相对位置,每个Topic可分为多个Partition。Offset是消息的唯一ID,并在序列中严格递增。搜索Offset采用二分查找找到小于目标Offset的最大索引位置(时间戳索引类似)。
- **Replica:**相当于副本,保证集群中节点上的 Partition 数据不因故障丢失。每个Partition有一个Replica-Leader,用于写入,同时拥有多个Follower用于记录Leader。如果Follower数据与Leader差距过大则踢出ISR。Replica又以log日志文件存储。
卡夫卡的消费模式
卡夫卡消息队列有两种最常见的消费模式。
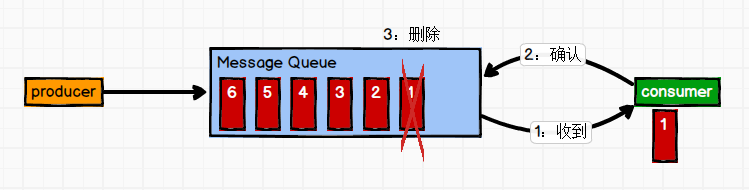
**一对一:**生产者将消息发送到消息队列后,由消费者从队列中拉取并消费,然后信息会被删除。
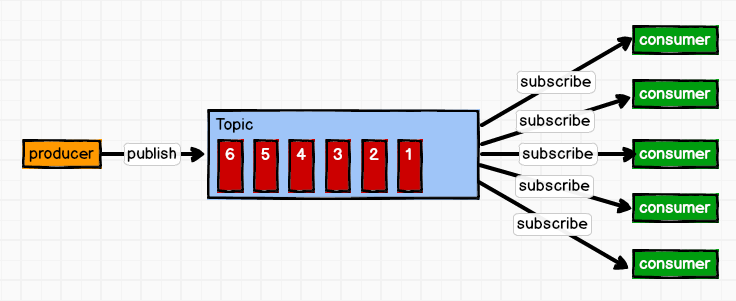
一对多:即发布-订阅模式。生产者将消息发送到逻辑队列(Topic)(逻辑队列存储在Cluster物理集群中),可以被多个消费者订阅,从而实现每个消费者独立从该主题中拉取消息,值得注意的是该模式下消息并不会在消费后立刻删除,而是会在删除前保留一段时间。
然而在实际业务中,这两种消费模式并不能覆盖所有常业务场景,因此也会衍生出如竞争消费和优先级消费等高级模式。
卡夫卡消息分配
- **手动分配:**通过手动分配完成哪个consumer消费哪个Partition。缺点是当Consumer节点故障后,Partition数据流受影响;当出现新的Consumer,需要重新分配Partition。
- **Rebalance:**通过设立Coordinator,自动识别故障的consumer节点或新增的consumer,实现自动分配。Consumer端应用程序在提交位移时,其实是向 Coordinator 所在的 Broker 提交位移。同样地,当 Consumer 应用启动时,也是向 Coordinator 所在的 Broker 发送各种请求,然后由 Coordinator 负责执行消费者组的注册、成员管理记录等元数据管理操作。
提高卡夫卡吞吐量和稳定性的方法
- **Producer:**批量发送(降低io次数)、数据压缩(降低带宽流量)。
- **Broker:**顺序写(提高吸入速度),消息索引,零拷贝。
- **Consumer:**Rebalance分配。
卡夫卡的缺点
- **重启操作:**重启broker后,Leader切换。与此同时数据仍在写入,导致重启的broker和当前的Leader数据产生差异,需要重新追赶后才能回切(由于其他broker也有可能需要重启),导致需要大量时间。
- **替换、扩容、缩容操作:**替换与重启操作类似,不过由于是重新写入,所以需要的时间更多。扩容和缩容都需要进行复制操作,因此也需要大量时间。
- **负载不均衡问题:**为降低某个Partition的IO写入而进行迁移,但同时也会引入新的IO负载,陷入恶性循环,需要复杂的解决方案。
缺点总结:
- 卡夫卡运维成本高。
- 负载不均衡问题严重。
- 没有缓存,依赖页缓存Page Cache。
- Controller、Coordinator和Broker在同一进程中,IO性能下降。