导出数据库为sql文件,在命令行中执行:
mysqldump -u root -p course-system > course-system.sql
DDL(Data Definition Language)数据定义语言
操作库
-- 创建库
create database db1;
-- 创建库是否存在,不存在则创建
create database if not exists db1;
-- 查看所有数据库
show databases;
-- 查看某个数据库的定义信息
show create database db1;
-- 修改数据库字符信息
alter database db1 character set utf8;
-- 删除数据库
drop database db1;
-- 使用某一数据库
use db1;
操作表
-- 创建表
create table student(
id int,
name varchar(32),
age int ,
score double(4,1),
birthday date,
insert_time timestamp
);
-- 查看表结构
desc 表名;
-- 查看创建表的SQL语句
show create table 表名;
-- 修改表名
alter table 表名 rename to 新的表名;
-- 添加一列
alter table 表名 add 列名 数据类型;
-- 删除列
alter table 表名 drop 列名;
-- 删除表
drop table 表名;
drop table if exists 表名 ;
DML(Data Manipulation Language)数据操作语言
增加 insert into
-- 写全所有列名
insert into 表名(列名1,列名2,...列名n) values(值1,值2,...值n);
-- 不写列名(所有列全部添加)
insert into 表名 values(值1,值2,...值n);
-- 插入部分数据
insert into 表名(列名1,列名2) values(值1,值2);
删除 delete
-- 删除表中数据
delete from 表名 where 列名 = 值;
-- 删除表中所有数据
delete from 表名;
-- 删除表中所有数据(高效 先删除表,然后再创建一张一样的表。)
truncate table 表名;
修改 update
-- 不带条件的修改(会修改所有行)
update 表名 set 列名 = 值;
-- 带条件的修改
update 表名 set 列名 = 值 where 列名=值;
DCL(Data Control Language)数据控制语言
管理用户
添加用户
语法:CREATE USER ‘用户名’@‘主机名’ IDENTIFIED BY ‘密码’;
删除用户
语法:DROP USER ‘用户名’@‘主机名’;
权限管理
查询权限
-- 查询权限
SHOW GRANTS FOR '用户名'@'主机名';
SHOW GRANTS FOR 'lisi'@'%';
授予权限
-- 授予权限
grant 权限列表 on 数据库名.表名 to '用户名'@'主机名';
-- 给张三用户授予所有权限,在任意数据库任意表上
GRANT ALL ON *.* TO 'zhangsan'@'localhost';
撤销权限
-- 撤销权限:
revoke 权限列表 on 数据库名.表名 from '用户名'@'主机名';
REVOKE UPDATE ON db3.`account` FROM 'lisi'@'%';
DQL(Data Query Language)数据查询语言
SQL查询的执行顺序
基础关键字
BETWEEN…AND (在什么之间)和 IN( 集合)
-- 查询年龄大于等于20 小于等于30
SELECT * FROM student WHERE age >= 20 && age <=30;
SELECT * FROM student WHERE age >= 20 AND age <=30;
SELECT * FROM student WHERE age BETWEEN 20 AND 30;
-- 查询年龄22岁,18岁,25岁的信息
SELECT * FROM student WHERE age = 22 OR age = 18 OR age = 25
SELECT * FROM student WHERE age IN (22,18,25);
is not null(不为null值) 与 like(模糊查询)、distinct(去除重复值)
-- 查询英语成绩不为null
SELECT * FROM student WHERE english IS NOT NULL;
_:单个任意字符
%:多个任意字符
-- 查询姓马的有哪些? like
SELECT * FROM student WHERE NAME LIKE '马%';
-- 查询姓名第二个字是化的人
SELECT * FROM student WHERE NAME LIKE "_化%";
-- 查询姓名是3个字的人
SELECT * FROM student WHERE NAME LIKE '___';
-- 查询姓名中包含德的人
SELECT * FROM student WHERE NAME LIKE '%德%';
-- 关键词 DISTINCT 用于返回唯一不同的值。
-- 语法:SELECT DISTINCT 列名称 FROM 表名称
SELECT DISTINCT NAME FROM student ;
EXISTS
EXISTS是返回boolean,不是返回的子查询。
使用方法:
SELECT xm FROM S WHERE EXISTS([conditions]...)
WITH:创建临时表
with 语句相当于建立了一张 临时虚拟表
即利用with子句为子查询的数据集作为一个内存临时表. 在内存中解析,提高执行效率.,并且提高SQL语句的可读性,用完即销毁。
语法 可以同时定义多个临时表
With
Subtable1 as (select 1...), //as和select中的括号都不能省略
Subtable2 as (select 2...), //后面的没有with,逗号分割,同一个主查询同级别地方,with子查询只能定义一次
…
Subtablen as (select n...) //与下面的实际查询之间没有逗号
Select ….
with子句相关总结:
1.使用with子句可以让子查询重用相同的with查询块,通过select调用(with子句只能被select查询块引用),一般在with查询用到多次情况下。在引用的select语句之前定义,同级只能定义with关键字只能使用一次,多个用逗号分割。 2.with子句的返回结果存到用户的临时表空间中,只做一次查询,反复使用,提高效率。 3.在同级select前有多个查询定义的时候,第1个用with,后面的不用with,并且用逗号隔开。 5.最后一个with 子句与下面的查询之间不能有逗号,只通过右括号分割,with 子句的查询必须用括号括起来 6.如果定义了with子句,而在查询中不使用,那么会报ora-32035 错误:未引用在with子句中定义的查询名。(至少一个with查询的name未被引用,解决方法是移除未被引用的with查询),注意:只要后面有引用的就可以,不一定非要在主查询中引用,比如后面的with 查询也引用了,也是可以的。 7.前面的with子句定义的查询在后面的with子句中可以使用。但是一个with子句内部不能嵌套with子句。 8.当一个查询块名字和一个表名或其他的对象相同时,解析器从内向外搜索,优先使用子查询块名字。 9.with查询的结果列有别名,引用的时候必须使用别名或*。 ———————————————— 版权声明:本文为CSDN博主「事后诸葛亮」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/zq9017197/article/details/5938514
ORDER BY:字段排序
语法:order by 子句
order by 排序字段1 排序方式1 , 排序字段2 排序方式2...
注意: 如果有多个排序条件,则当前边的条件值一样时,才会判断第二条件。
如果使用默认的 utf8mb4 字符编码,中文按照偏旁部首进行排序,拼音排序用ORDER BY CONVERT(列名 USING GBK) ASC/DESC
-- 例子
SELECT * FROM person ORDER BY math; --默认升序
SELECT * FROM person ORDER BY math desc; --降序
GROUP BY:字段分组
group by的过程解析
如图所示,使用GROUP BY name,就相当于使用name进行分组,name相同的都压缩到一行中去,如表3。
然饿,因为每一行只能允许存在一个确定的值,所以需要对这种有多个的值的格子,进行多个输入、一个输出的聚合函数进行处理。
所以说GROUP BY能查询的字段只有分组字段、聚合函数。
-- 按照性别分组。分别查询男、女同学的平均分
SELECT sex , AVG(math) FROM student GROUP BY sex;
group by 多个字段
如group by name,number,我们可以把name和number 看成一个整体字段,以他们整体来进行分组的。
场景:对某一列的数目进行筛选
比如至少玩过某两款游戏的玩家ID,就可以用count+group by+having进行条件筛选。比如:
WHERE GNAME in ('王者荣耀','帝国时代')
GROUP BY player.PID
HAVING COUNT(PID)>=2;
HAVING:组条件
HAVING 大多数情况下和结合 GROUP BY 来使用,但不是一定要结合 GROUP BY 来使用
SELECT cno, COUNT(*) nums FROM tbl_student_class GROUP BY cno HAVING COUNT(*) = 3;
INNER JOIN
隐式内连接
使用where条件消除无用数据
-- 查询员工表的名称,性别。部门表的名称
SELECT emp.name,emp.gender,dept.name FROM emp,dept WHERE emp.`dept_id` = dept.`id`;
SELECT
t1.name, -- 员工表的姓名
t1.gender,-- 员工表的性别
t2.name -- 部门表的名称
FROM
emp t1,
dept t2
WHERE
t1.`dept_id` = t2.`id`;
显式内连接
-- 语法:
select 字段列表 from 表名1 [inner] join 表名2 on 条件
-- 例如:
SELECT * FROM emp INNER JOIN dept ON emp.`dept_id` = dept.`id`;
SELECT * FROM emp JOIN dept ON emp.`dept_id` = dept.`id`;
外连接查询
LEFT JOIN
左外连接 – 查询的是左表所有数据以及其交集部分
-- 语法:select 字段列表 from 表1 left [outer] join 表2 on 条件;
-- 例子:
-- 查询所有员工信息,如果员工有部门,则查询部门名称,没有部门,则不显示部门名称
SELECT t1.*,t2.`name` FROM emp t1 LEFT JOIN dept t2 ON t1.`dept_id` = t2.`id`;
RIGHT JOIN
右外连接 – 查询的是右表所有数据以及其交集部分
-- 语法:
select 字段列表 from 表1 right [outer] join 表2 on 条件;
-- 例子:
SELECT * FROM dept t2 RIGHT JOIN emp t1 ON t1.`dept_id` = t2.`id`;
CASE 子句
Case具有两种格式。简单Case函数和Case搜索函数。
--简单Case函数
CASE sex
WHEN '1' THEN '男'
WHEN '2' THEN '女'
ELSE '其他' END
--Case搜索函数
CASE
WHEN sex = '1' THEN '男'
WHEN sex = '2' THEN '女'
ELSE '其他' END
这两种方式,可以实现相同的功能。简单Case函数的写法相对比较简洁,但是和Case搜索函数相比,功能方面会有些限制,比如写判断式。
使用示例:
INNER JOIN battle ON
CASE
WHEN battle.WINNER = 'PLAYER1' THEN battle.PLAYER1
WHEN battle.WINNER = 'PLAYER2' THEN battle.PLAYER2
ELSE NULL -- 如果 WINNER 不是 'PLAYER1' 或 'PLAYER2',可以返回 NULL 或其他适当的值
END = player.PID
外键
外键的设置
用SQL语言设置外键:`[ CONSTRAINT `外键别名`] FOREIGN KEY (`受限制的列名`) REFERENCES `引用的表` (`引用的列名`)`
CREATE TABLE `S` (
`xh` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`xm` varchar(255) NOT NULL,
`xb` varchar(255) DEFAULT NULL,
`csrq` varchar(255) DEFAULT NULL,
`jg` varchar(255) DEFAULT NULL,
`sjhm` varchar(255) DEFAULT NULL,
`yxh` varchar(255) DEFAULT NULL,
PRIMARY KEY (`xh`),
KEY `idx1` (`yxh` DESC,`xm`) USING BTREE /*!80000 INVISIBLE */,
KEY `学生表S院系号` (`yxh`),
CONSTRAINT `学生表S院系号` FOREIGN KEY (`yxh`) REFERENCES `D` (`yxh`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
外键是各个表之间的约束和联系,让数据更加合理。
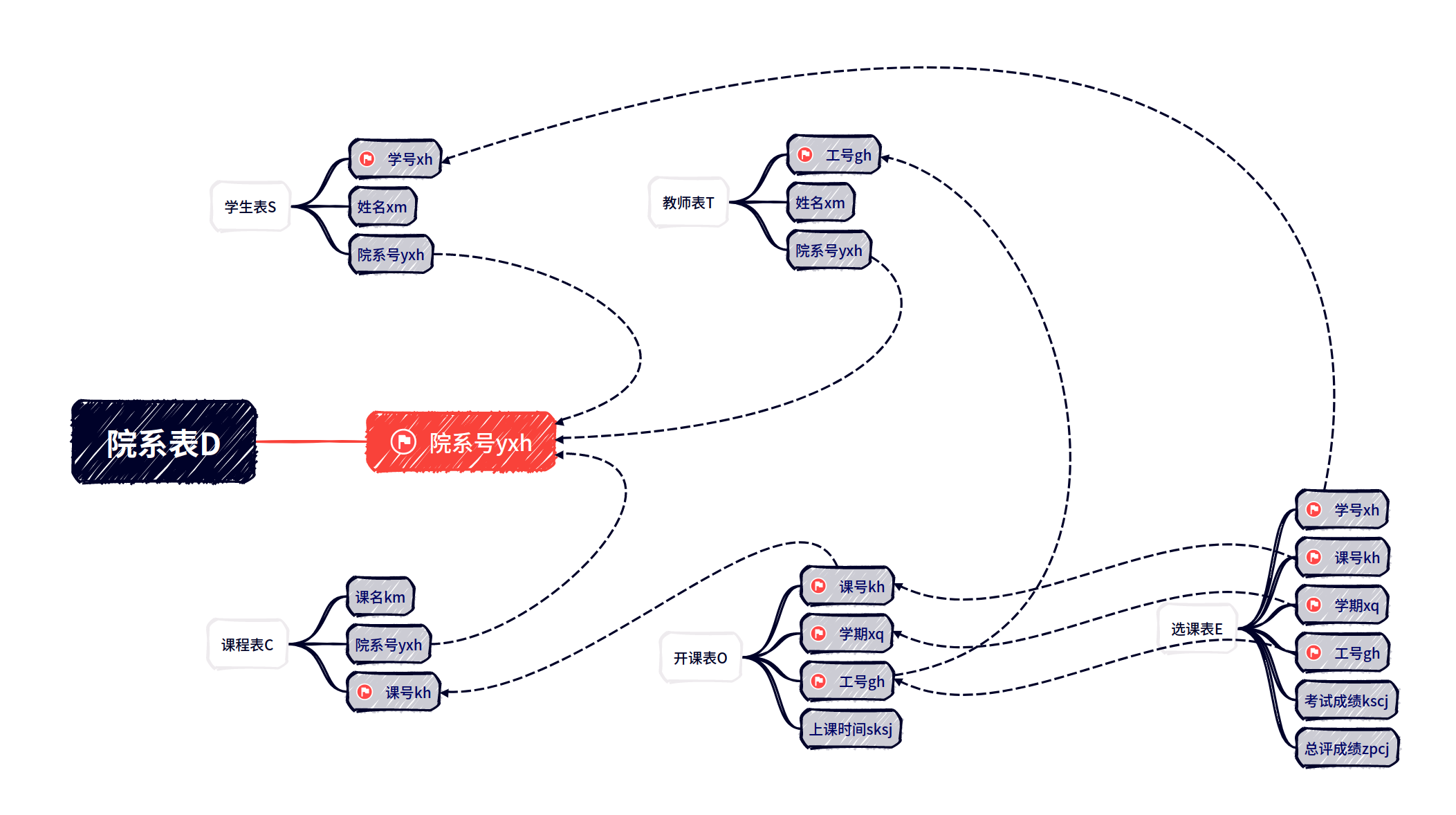
外键设置后,对添加和删除数据元素就有了先后顺序的要求。
添加记录会出现的错误
如果想要在学生表S中添加院系号为04的学生,直接执行
INSERT INTO `dbclass-school`.`S` (`xh`, `xm`, `xb`, `csrq`, `jg`, `sjhm`, `yxh`) VALUES ('1108', 'Kelvin', '男', '1993-08-16', '加州', '16301254638', '05');
会出现报错:
ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`dbclass-school`.`S`, CONSTRAINT `学生表S院系号` FOREIGN KEY (`yxh`) REFERENCES `D` (`yxh`))
删除记录会出现的错误
在被引用的外键D.yxh删除记录,也会出现报错。
mysql> DELETE FROM D WHERE yxh='01';
ERROR 1451 (23000): Cannot delete or update a parent row: a foreign key constraint fails (`dbclass-school`.`S`, CONSTRAINT `学生表S院系号` FOREIGN KEY (`yxh`) REFERENCES `D` (`yxh`))
正确的增删顺序是必要的
有顺序地增加记录
# 先添加D表中的院系号yxh
mysql> INSERT INTO `dbclass-school`.`D` (`yxh`,`Mc`,`dz`,`lxdh`) VALUES('04','美术学院','上大东校区五号楼','1234675427');
Query OK, 1 row affected (0.01 sec)
mysql> SELECT * FROM D;
+-----+-----------------+--------------------------+------------+
| yxh | Mc | dz | lxdh |
+-----+-----------------+--------------------------+------------+
| 01 | 计算机学院 | 上大东校区三号楼 | 65347567 |
| 02 | 通讯学院 | 上大东校区二号楼 | 65341234 |
| 03 | 材料学院 | 上大东校区四号楼 | 65347890 |
| 04 | 美术学院 | 上大东校区五号楼 | 1234675427 |
+-----+-----------------+--------------------------+------------+
4 rows in set (0.00 sec)
# 之后才能插入该院系号的学生
mysql> INSERT INTO `dbclass-school`.`S` (`xh`, `xm`, `xb`, `csrq`, `jg`, `sjhm`, `yxh`) VALUES ('1109', 'Eva', '女', '1993-08-16', '加州', '16301254638', '04');
Query OK, 1 row affected (0.00 sec)
mysql> SELECT * FROM S;
+------+-----------+------+------------+--------+-------------+------+
| xh | xm | xb | csrq | jg | sjhm | yxh |
+------+-----------+------+------------+--------+-------------+------+
| 1101 | 李明 | 男 | 1993-03-06 | 上海 | 13613005486 | 02 |
| 1102 | 刘晓明 | 男 | 1992-12-08 | 安徽 | 18913457890 | 01 |
| 1103 | 张颖 | 女 | 1993-01-05 | 江苏 | 18826490423 | 01 |
| 1104 | 刘晶晶 | 女 | 1994-11-06 | 上海 | 13331934111 | 01 |
| 1105 | 刘成刚 | 男 | 1991-06-07 | 上海 | 18015872567 | 01 |
| 1106 | 李二丽 | 女 | 1993-05-04 | 江苏 | 18107620945 | 01 |
| 1107 | 张晓峰 | 男 | 1992-08-16 | 浙江 | 13912341078 | 01 |
| 1108 | Kelvin | 男 | 1993-08-16 | 加州 | 16301254638 | 03 |
| 1109 | Eva | 女 | 1993-08-16 | 加州 | 16301254638 | 04 |
+------+-----------+------+------------+--------+-------------+------+
9 rows in set (0.00 sec)
有顺序地删除记录
# 在外键被引用的时候不能直接删除被引用的内容
mysql> DELETE FROM D WHERE yxh=04;
ERROR 1451 (23000): Cannot delete or update a parent row: a foreign key constraint fails (`dbclass-school`.`S`, CONSTRAINT `学生表S院系号` FOREIGN KEY (`yxh`) REFERENCES `D` (`yxh`))
# 应该先删除学生表中引用该院系号的记录
mysql> DELETE FROM S WHERE yxh=04;
Query OK, 1 row affected (0.01 sec)
# 最后才能删除逻辑上最底层的记录
mysql> DELETE FROM D WHERE yxh=04;
Query OK, 1 row affected (0.00 sec)
错误提示
Operand should contain 1 column(s)
原因是我的子查询查询出的数据不止一个字段,但是我却在整体SQL中 把子查询出来的结果 作为一个字段的 NODE_ID 了
SQL 参数错误
这个问题的原因有很多,下面列出碰到的不易看出错误的:
INNER JOIN rank ON player.RANK=rank.RID
应该改为:
INNER JOIN `rank` ON player.RANK=`rank`.RID
因为rank是sql中的保留关键字,作为表名需要用``括起来,当然最好是不要使用这样的名字作为表名。