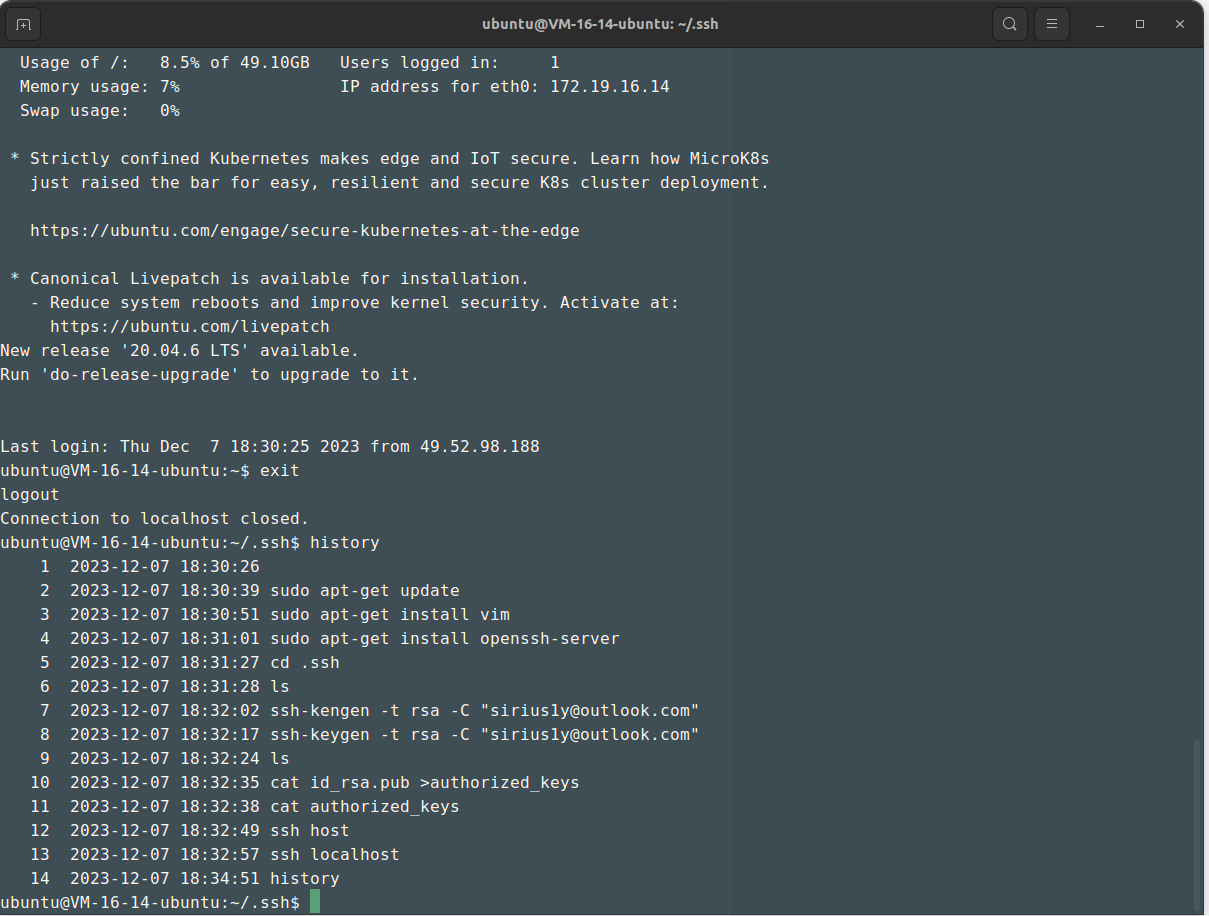
生成密钥并实现自我登录
sudo apt-get install vim
sudo apt-get install openssh-server
cd .ssh
ssh-keygen -t rsa -C "sirius1y@outlook.com"
cat id_rsa.pub > authorized_keys
安装java
sudo apt-get install openjdk-8-jre openjdk-8-jdk
检查java是否安装完成
java -version
下载hadoop
网站:https://archive.apache.org/dist/hadoop/common/hadoop-2.7.0/
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.0/hadoop-2.7.0.tar.gz
# 解压
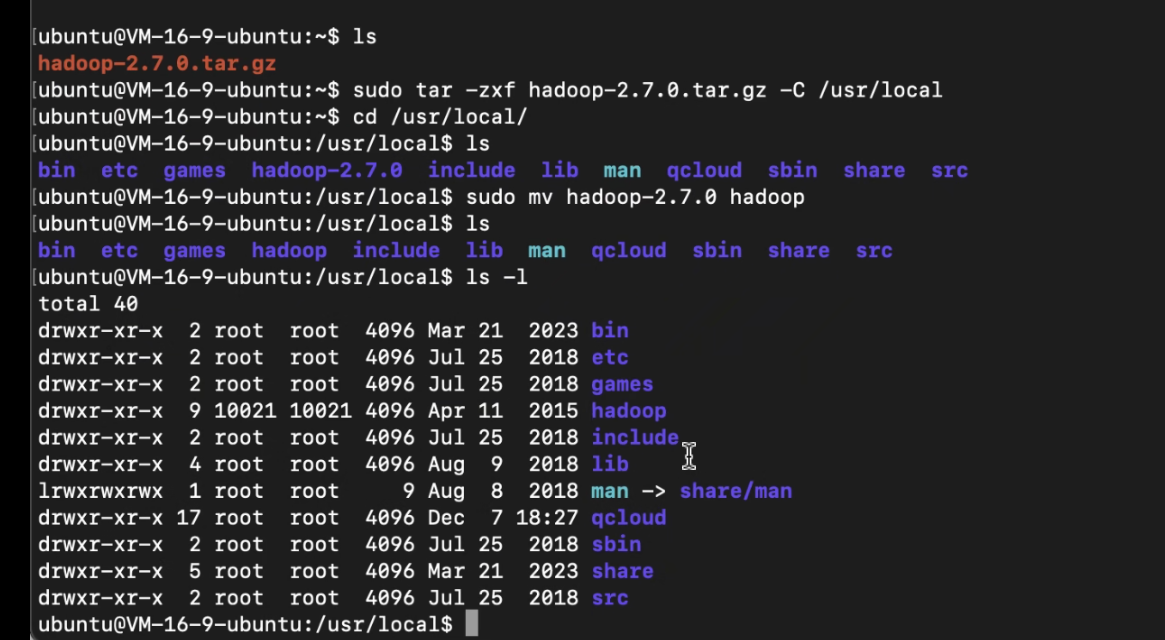
sudo tar -zxf hadoop-2.7.0.tar.gz -C /usr/local
修改所有权:
cd /usr/local
sudo mv hadoop-2.7.0/ hadoop
sudo chown -R ubuntu ./hadoop
设置JAVA_HOME环境变量
sudo vim ~/.bashrc
# 把下面内容添加到末尾
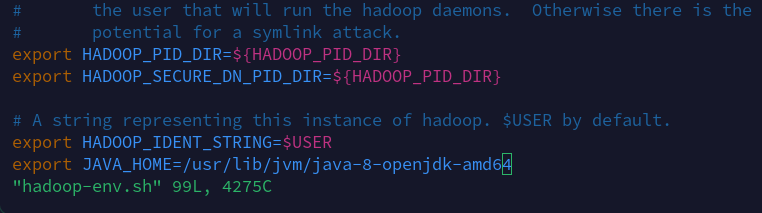
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64

删除~/.ssh/kown_hosts
创建镜像之后新建示例
发现能够存在hadoop
—————–创建两台镜像
取机器的昵称
sudo vim /etc/hostname添加自己的名字

sudo vim /etc/hosts,这里都是使用的内网IP地址
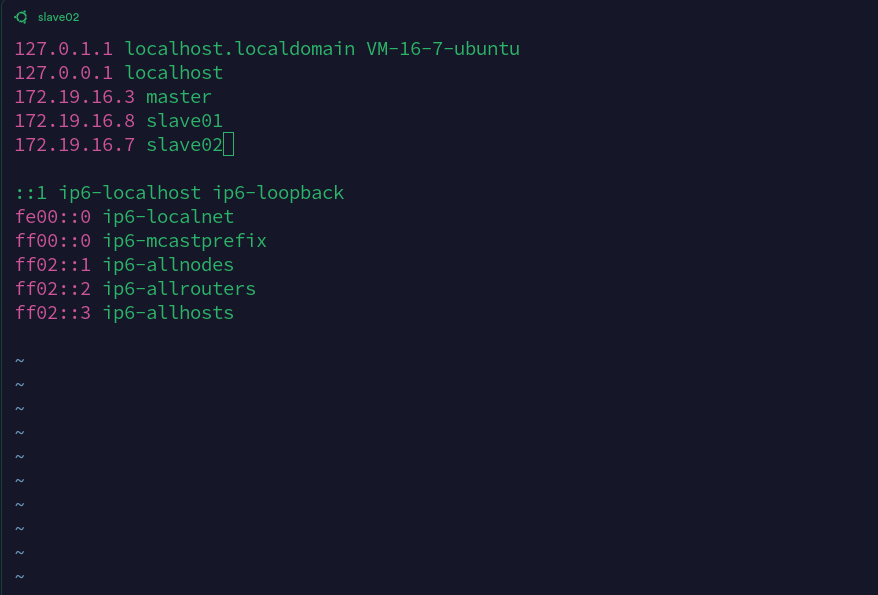
重启之后,每台机器的名字都变了
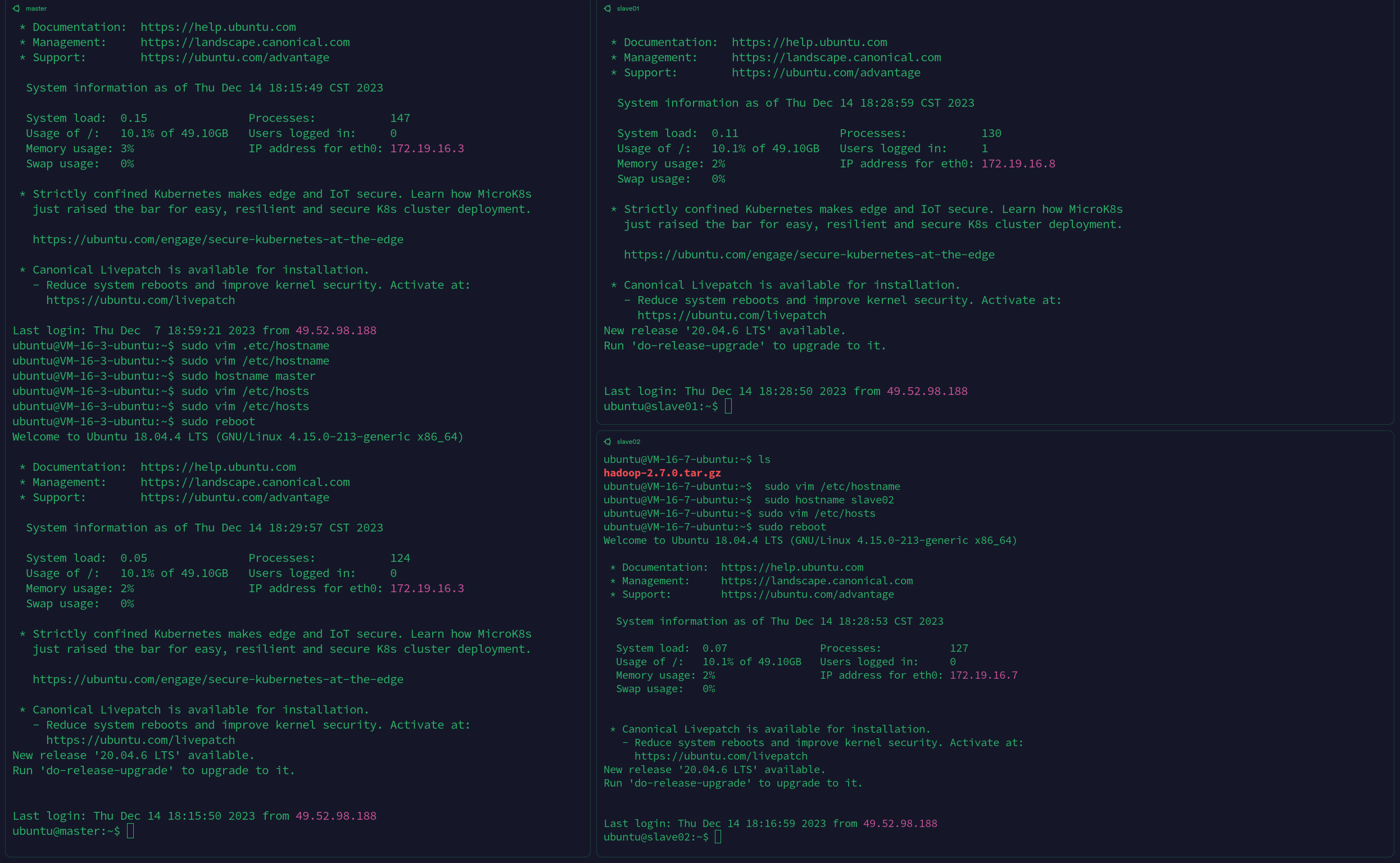
并且可以通过直接ssh master,ssh slave01的方式直接访问;
修改master和slaves配置文件
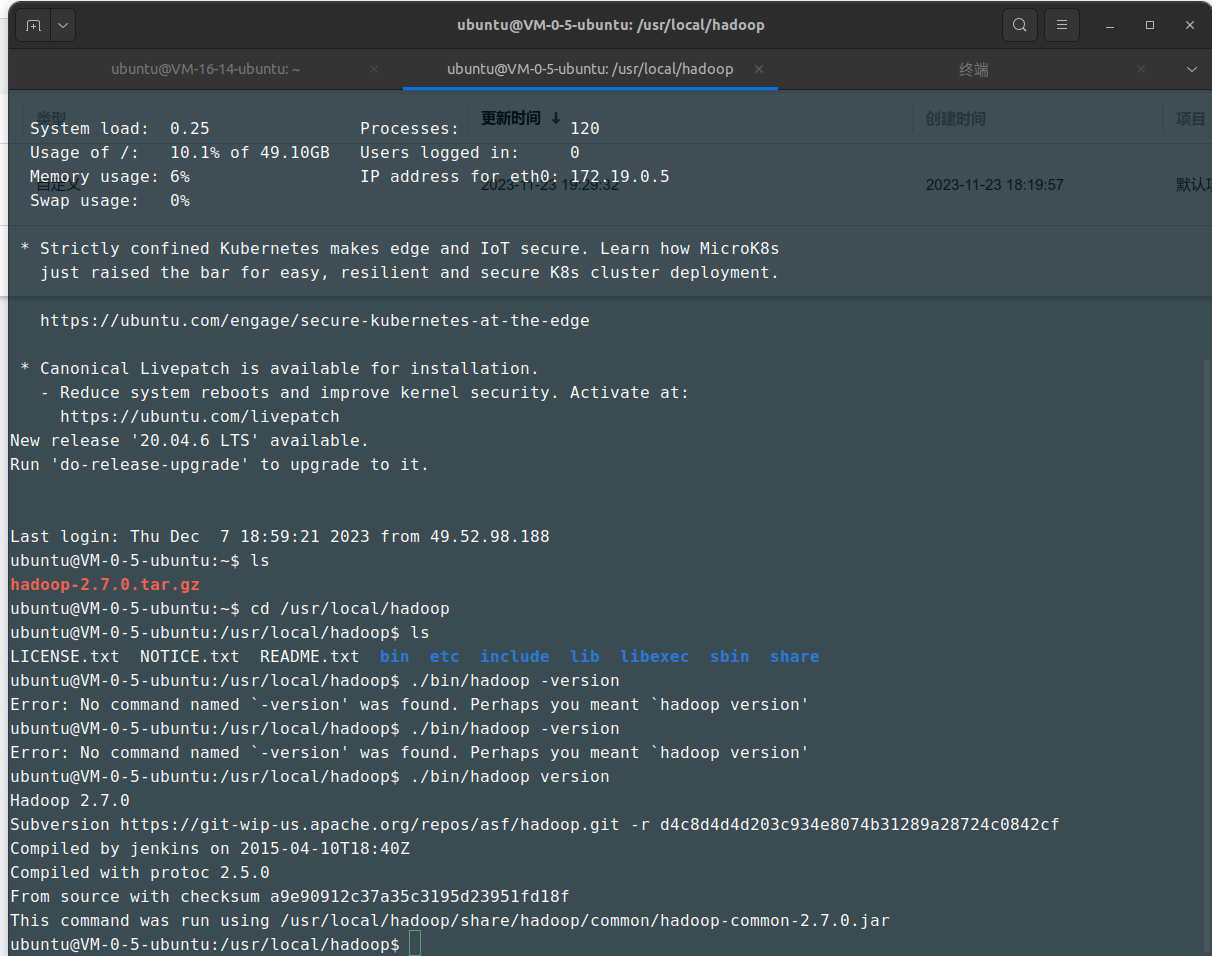
cd /usr/local/hadoop/etc/hadoop/
修改这些配置文件
配置文件详情:
https://www.aidac-shu.com/courses/的reference部分

# slaves
slave01
slave02
# core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
# hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
# mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
# yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>

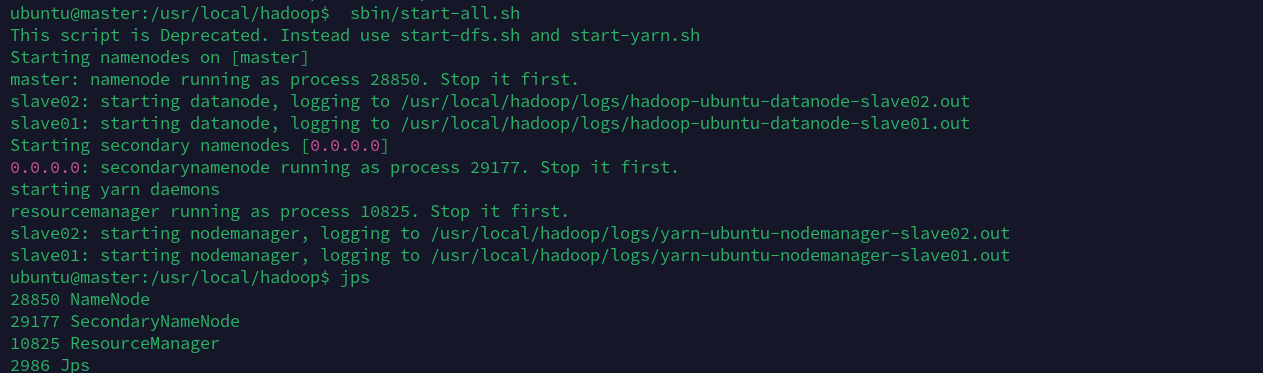
用jps检查java进程执行情况

启动hadoop
/usr/local/hadoop/bin/hdfs namenode -format
在这之后会得到一大串的输出,最后会出现两个0,表示成功执行:
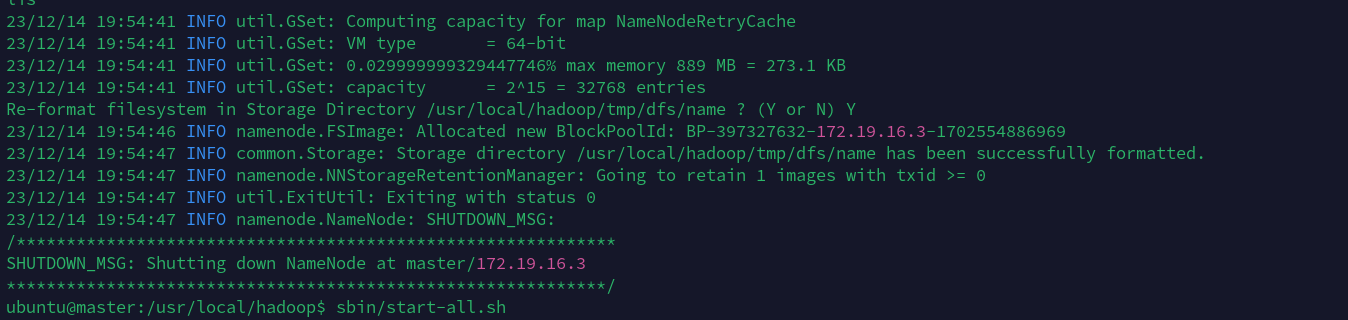
/usr/local/hadoop/sbin/start-all.sh
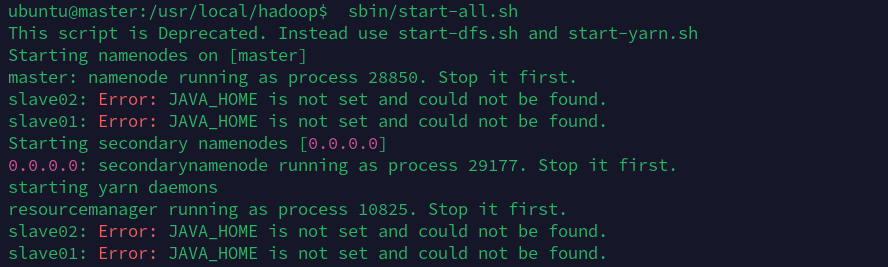
刚开始启用这条命令的时候会出现JAVA_HOME没有设置的情况,但是我已经在~/.bashrc中设置了(尝试过在/etc/bash.bashrc也不行)
原因很有可能是环境变量并没有作用到/usr/local/hadoop中。
然后我在/usr/local/hadoop/etc/hadoop/hadoop-env.sh中设置了export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64之后(在master和两台slave上都设置)了,在启用命令sbin/start-all.sh就能成功执行。


HDFS使用
添加HADOOP环境变量
可以把HADOOP的位置/usr/local/hadoop/添加到环境变量中,就可以直接访问hadoop和hdfs了
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin

文件操作
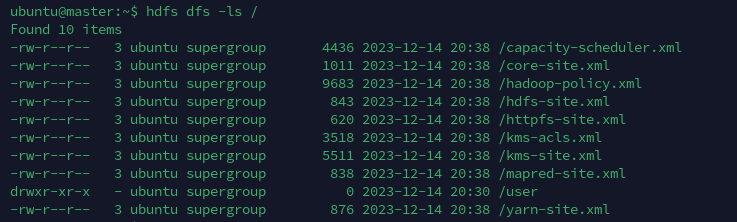
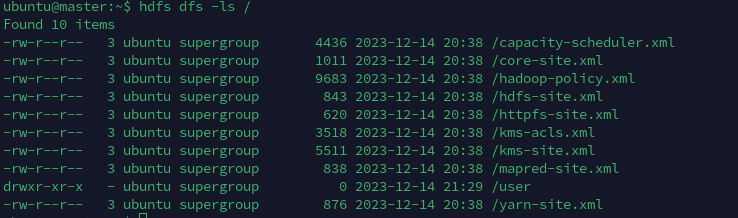
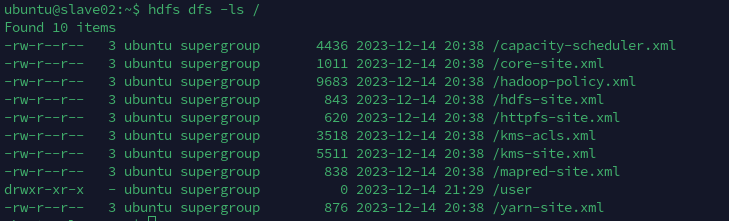
在slave01上把文件放入到/中: hdfs dfs -put etc/hadoop/*.xml /
使用命令hdfs dfs -ls /会列出文件系统/下的所有文件
在这里演示,在文件系统中先创建一个目录/user/input/,再把文件try.sh放入其中,再进行查看
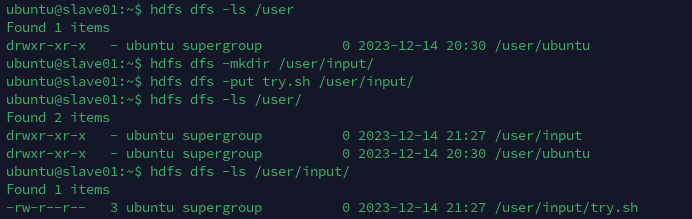
需要注意的是,需要在目录创建成功之后再进行put操作,否则只会创建目录,但是不会把文件放入其中的操作。(好奇怪)
另外,在任何一个结点上创建的文件都会同步到其他几台机器上。
配置HIVE
下载hive
在master上的主目录上,运行
wget https://dlcdn.apache.org/hive/hive-1.2.2/apache-hive-1.2.2-bin.tar.gz
解压到主目录下
ubuntu@master:~$ tar -zxvf apache-hive-1.2.2-bin.tar.gz -C ~
更改名字+更改所有权
# 改名 mv
ubuntu@master:~$ ls
apache-hive-1.2.2-bin apache-hive-1.2.2-bin.tar.gz hadoop-2.7.0.tar.gz
ubuntu@master:~$ mv apache-hive-1.2.2-bin hive
ubuntu@master:~$ ls
apache-hive-1.2.2-bin.tar.gz hadoop-2.7.0.tar.gz hive
# 更改所有权 chown
ubuntu@master:~$ sudo chown -R ubuntu ./hive
把hive添加到环境变量中
# ~/.bashrc
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export HIVE_HOME=/home/ubuntu/hive/
export PATH=$PATH:$HIVE_HOME/bin
完成之后更新 source ~/.bashrc
运行hive
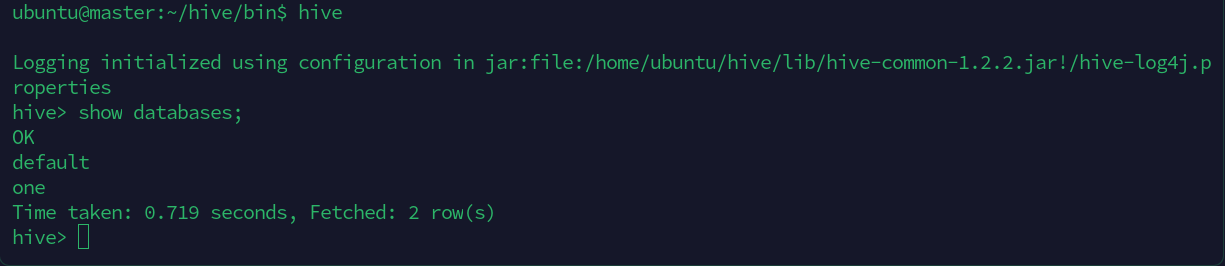
# HiveSQL
# 创建数据库
CREATE DATABASE one;
# 查看数据库
SHOW DATABASES;
# 切换数据库
USE database_name;
# 查看该数据库下面的所有表
SHOW TABLES;
# 新建表
CREATE TABLE employees(
id INT,
name STRING,
department STRING
);
# 插入数据
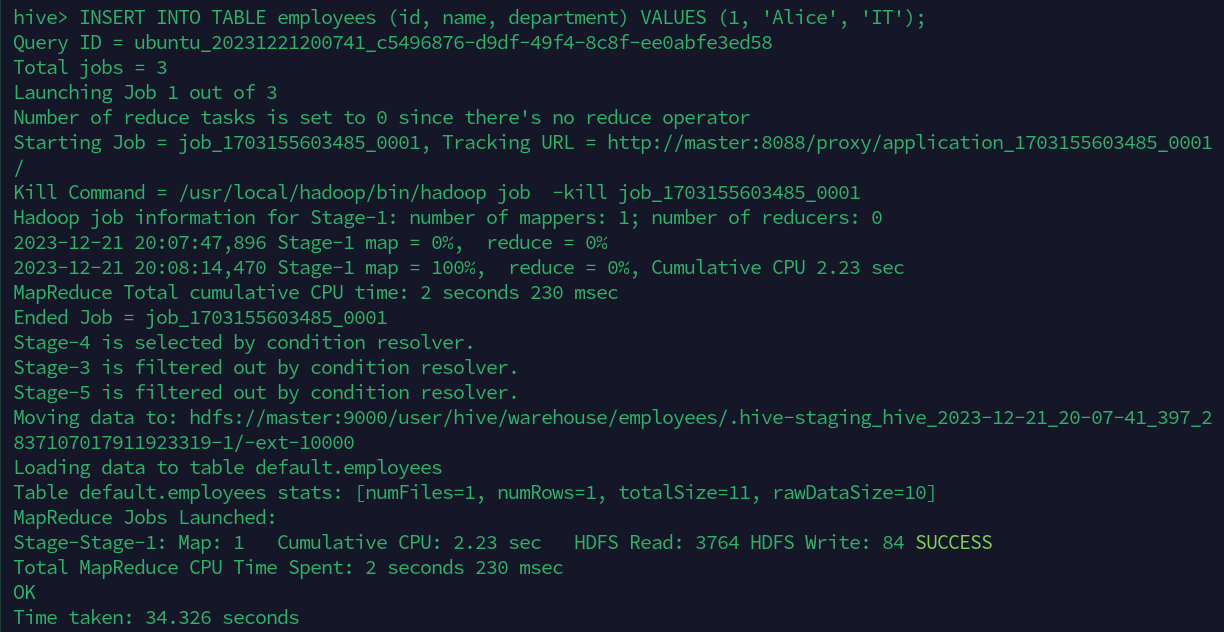
INSERT INTO TABLE employees (id, name, department) VALUES (1, 'Alice', 'IT');
INSERT INTO TABLE employees (id, name, department) VALUES (2, 'Bob', 'HR');
INSERT INTO TABLE employees (id, name, department) VALUES (3, 'Charlie', 'Finance');
# 查询操作
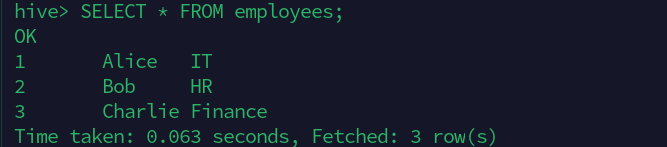
SELECT * FROM employees;
SELECT * FROM employees WHERE department='IT';
插入过程中的一些截图,他这个插入还比较麻烦:
分为了三个部分进行执行。
查询展示: