计算机网络
TCP
TCP为什么要进行三次握手?
三次握手是建立网络连接的过程,确保双方能够正确地进行数据传输。
第一次握手SYN:客户端向服务端发送SYN请求同步信号,并初始化客户端序列号;
第二次握手SYN+ACK:服务端收到了客户端发送的SYN信号后回复ACK确认收到,同时也发送SYN,指定自己的初始序列号;
第三次握手ACK:客户端收到服务端的ACK+SYN后,回复一个ACK,表示已经收到服务端的ACK+SYN。这个包的序列会加一,表示客户端已经准备好和服务端进行数据传输了。
为什么是三次握手?不是两次或者四次
原因1:阻止重复的历史连接初始化
如果是两次握手的话,因网络堵塞的问题,客户端发送了两次SYN给服务端,服务端收到了第一个SYN的时候,就回复SYN+ACK给客户端,并进入了ESTABLISHED状态。而客户端这边收到了服务端旧的ACK+SYN,会认为这是历史连接从而发送RST报文,使服务端断开连接。
原因2:同步双方的序列号
TCP协议的双方都必须要维护一个序列号。两次握手只能保证一方的序列号被接收。
原因3:避免资源浪费
如果是两次握手,那么服务端在收到SYN后回复ACK的时候就要主动建立连接,要是网络堵塞,对面发了好多个SYN来,那完蛋了,建立了好多个TCP连接,造成了资源浪费。
TCP的四次挥手
四次挥手是指在TCP断开连接的过程中发生的,一般是由客户端发起,服务端完成最后的断开。
因为TCP是全双工通信,所以需要两边都要通知对方停止数据传输,故需要四次挥手保证断开连接。
具体流程:(刚开始双方都处于ESTABLISHED状态)
1.客户端向服务端发起FIN报文,表示客户端不再发送数据;(客户端进入FIN_WAIT_1中状态)
2.服务端收到FIN报文后,回复一个ACK表示收到;(服务端进入CLOSED_WAIT状态,客户端收到ACK后进入FIN_WAIT_2状态)
3.服务端向客户端发起FIIN报文,表示服务端也不再发送数据;(服务端进入LAST_ACK状态)
4.客户端收到服务端的FIN报文后,也回复一个ACK。(客户端进入TIME_WAIT状态)
发送端在最后会进入到TIME_WAIT的状态,
为什么有TIME_WAIT状态?
原因1:保证历史连接中的数据不会干扰下一次连接。
原因2:保证被动关闭连接。如果服务端没有TIME_WAIT状态直接close的话,要是服务端没有收到客户端最后一次发送的ACK会重发FIN,如果服务器已经处于CLOSE状态,就会返回RST报文,RST报文会被服务端认定为错误。
为什么TIME_WAIT的时间是2MSL?
MSL是报文的最大生存时间,超过这个时间的报文都会被丢弃。两个MSL时间可以保证客户端发送的ACK报文可以到达服务端+服务端要是在第一个MSL中没有收到ACK可以重发一次FIN到客户端,并保证能够到达客户端。
HTTP
GET方法和POST方法有什么区别?
用途:GET方法一般用于请求服务器上的数据;POST方法用于向服务器提交数据。
请求参数:GET方法的请求参数一般放在URL中,POST的请求参数一般放在请求体中。
幂等:多次执行相同的操作,结果都相同。
幂等行:GET方法是安全幂等的,POST不是幂等的。
缓存机制:GET请求会被浏览器主动cache,如果下一次传输的数据相同,就会返回浏览器中的内容;而POST不会。
GET的请求参数会被保存在浏览器的历史记录中,而POST中的参数不会保留
时间消耗:GET产生一个TCP数据包,浏览器会把header和data一起发送出去,服务器相应200;
POST产生两个TCP数据包,浏览器先发送hader,服务器相应100(继续发送),浏览器再发送data,服务器相应200
什么情况下会使用POST读取数据?
- 当查询的数据量很多,GET方式的URL太长太大,GET方式大概是4KB,POST上限是8MB
- 当对数据的安全性有更高要求的时候,可以在POST的请求体中对数据进行加密
HTTP版本对比
HTTP/0.9
- 只支持GET方法
HTTP/1.0
- 支持多种请求方式
- 引入了请求头和响应头
- 引入状态码
不支持长连接
HTTP/1.1
- 支持长连接
- 管道网络传输(可以同时发送A、B请求,不必等待A响应)
但是管道网络传输存在队头阻塞的问题
头部冗余
没有请求优先级
请求只能通过客户端推送,服务器不能主动推送
HTTP/2
- 使用HPACK进行头部压缩
- 把数据部分压缩成头信息帧和数据帧
- 并发传输:引入了stream的概念,多个Stream复用一条TCP连接,通过streamID识别,不同stream的帧可以乱序发送
- 支持服务器推送
HTTPS
和HTTP对比
优点
安全性更高
缺点
HTTPS涉及到了加解密的过程,所以对服务器的负荷会高一些;
握手阶段的延迟比较高,因为还有SSL/TLS握手;
加密过程
HTTPS采用了对称加密+非对称加密的混合加密模式
在通信建立之前,使用非对称加密交换会话密钥;
通信建立之后,使用会话密钥实现对称加密,进行消息传递
具体流程
- 客户端向服务端发送ClientHello
- 服务器生成一对公私钥,并把公钥注册到CA,得到数字证书
- 服务器对客户端响应ServerHello,并把数字证书传给客户端
- 客户端使用浏览器中内置的CA公钥对数字证书进行验证
- 可信后取出数字证书中的服务器公钥,随机生成一个随机数,并把他用公钥进行加密,并传递给服务端
- 服务端使用服务端私钥进行解密,得到随机数
- 客户端和服务端使用这个随机数(会话密钥)进行通信
密码学相关知识复习
摘要算法和数字签名
摘要算法可以保证内容没有被篡改;数字签名可以保证发送者身份。
数字签名使用非对称加密,发送方使用私钥对摘要进行加密。接收方使用公钥对加密的摘要进行解密,若能使用公钥解开说明发送者身份正确。并将其与文件的摘要进行比较,若一致,说明文件没有被篡改。
数字证书
技术来源:在上述的数字签名的算法中,接收方是用到了公钥对加密摘要进行解密,而这把公钥有可能会遭遇中间人攻击被替换。这就是数字证书的起源。
实现过程
- 服务端生成的一堆密钥,把服务端密钥给CA,CA用CA私钥加密服务端公钥得到数字签名和数字证书;
- 服务端把数字证书(包含服务端公钥)+CA数字签名给客户端;
- 客户端的浏览器(内置CA公钥),对CA数字签名进行验证,说明服务器公钥可信;
- 客户端使用服务器公钥加密数据文件发送给服务器;
- 服务器再用他的私钥进行文件解密。
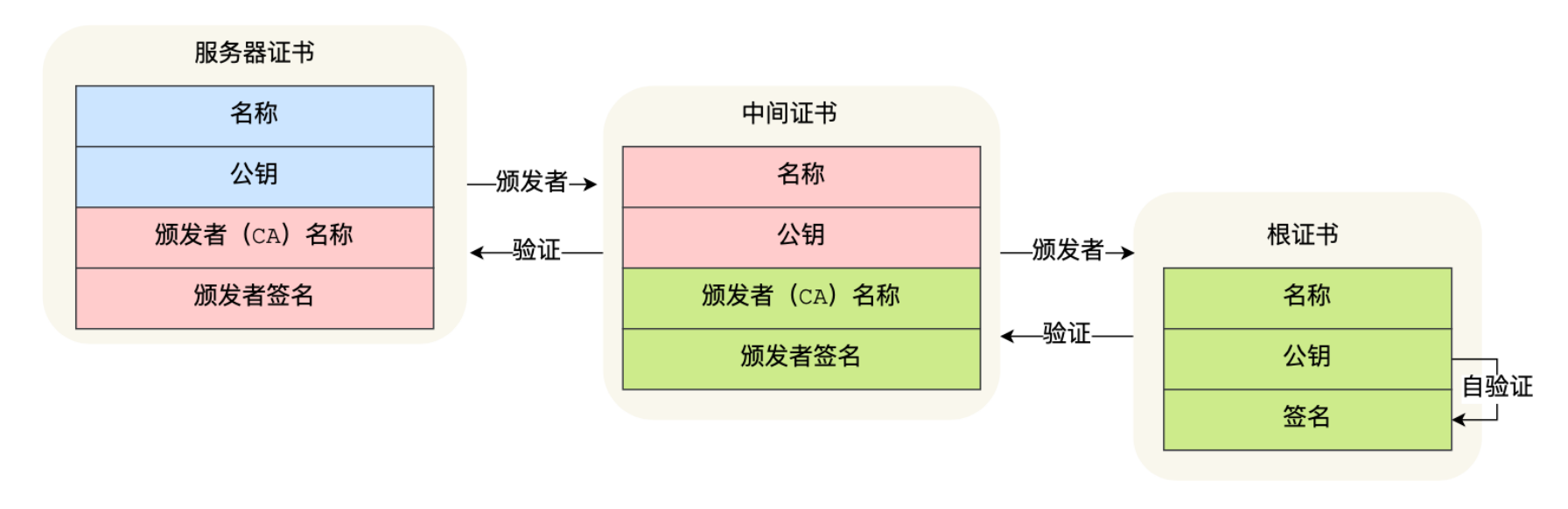
证书信任链
证书信任链是验证数字证书过程的一部分。
客户端会从服务器证书-中间证书-根CA证书依次验证,若中间有一环出现了问题,那么这个数字证书就是不可信的。
Token和Cookie的选择
在Web应用程序中,Token和Cookie都是用于用户鉴权和会话管理的常用机制。选择Token还是Cookie取决于具体的应用场景和需求。
Token
Token 通常用于现代Web应用程序,特别是在单页应用(SPA)和移动应用中。常见的Token类型包括JWT(JSON Web Token)。
优点:
- 无状态性:Token是无状态的,服务端不需要存储会话数据,便于扩展。
- 跨域支持:Token可以通过HTTP头传输,支持跨域请求。
- 移动友好:适用于移动应用和API调用。
缺点:
- 安全性:如果Token泄露,可能会导致安全风险,通常需要实现Token的过期和刷新机制。
- 复杂性:实现Token管理和安全机制需要更多的开发工作。
示例:
- 用户登录后,服务端生成一个JWT并返回给客户端。
- 客户端将Token存储在本地存储(LocalStorage)或会话存储(SessionStorage)中。
- 每次请求时,客户端将Token添加到HTTP头中进行验证。
// 发送带有Token的请求
fetch('https://api.example.com/protected', {
method: 'GET',
headers: {
'Authorization': 'Bearer ' + token
}
})
.then(response => response.json())
.then(data => console.log(data));
Cookie
Cookie 是传统的会话管理机制,主要用于Web浏览器中存储和传输会话信息。
优点:
- 简单易用:浏览器原生支持,使用简单,适用于大多数Web应用。
- 安全控制:可以通过设置HttpOnly、Secure、SameSite等属性来提高安全性。
- 持久性:可以设置过期时间,使其在会话结束后继续存在。
缺点:
- 跨域限制:默认情况下,Cookie在跨域请求中有一定限制。
- 服务器负担:服务器需要存储会话数据,可能增加负担。
示例:
- 用户登录后,服务端生成一个Session ID并存储在服务器上,同时将Session ID作为Cookie返回给客户端。
- 每次请求时,浏览器会自动携带Cookie进行验证。
// 使用浏览器自动发送Cookie的请求
fetch('https://api.example.com/protected', {
method: 'GET',
credentials: 'include'
})
.then(response => response.json())
.then(data => console.log(data));
用户鉴权
用户鉴权是确保用户身份合法的过程。常见的用户鉴权机制包括:
1. 基于Session的鉴权
Session ID存储在服务器和客户端的Cookie中,用户登录后,服务器生成一个Session ID并返回给客户端,客户端在后续请求中携带这个Session ID进行身份验证。
实现步骤:
- 用户登录,服务器生成Session ID并存储在服务器的Session存储中。
- 服务器将Session ID作为Cookie返回给客户端。
- 客户端在后续请求中自动携带Cookie。
- 服务器根据Session ID验证用户身份。
2. 基于Token的鉴权
Token通常使用JWT实现,用户登录后,服务器生成一个Token并返回给客户端,客户端在后续请求中携带这个Token进行身份验证。
实现步骤:
- 用户登录,服务器生成JWT并返回给客户端。
- 客户端将JWT存储在LocalStorage或SessionStorage中。
- 客户端在后续请求中将JWT添加到HTTP头中。
- 服务器验证JWT的有效性和合法性。
3. OAuth鉴权
OAuth是一种开放的授权标准,允许用户授权第三方应用访问其资源而无需暴露密码。常用于社交登录、第三方API访问等场景。
实现步骤:
- 用户在第三方应用中登录,第三方应用请求OAuth授权码。
- 用户授权,第三方应用获取授权码。
- 第三方应用使用授权码向OAuth服务器请求Token。
- OAuth服务器返回Token,第三方应用使用Token访问受保护资源。
选择Token还是Cookie
选择Token还是Cookie取决于具体的应用场景和需求:
- 单页应用(SPA)和移动应用:通常使用Token(如JWT)进行鉴权,因其无状态性和跨域支持。
- 传统Web应用:通常使用Cookie和Session进行鉴权,因其简单易用和浏览器原生支持。
- 需要跨域请求:Token更为合适,因其可以通过HTTP头传输,支持跨域请求。
- 需要更高的安全控制:Cookie可以设置HttpOnly、Secure等属性,提高安全性。
综合考虑应用的架构、需求和安全性,选择合适的鉴权机制,可以确保用户身份验证的安全性和有效性。
JWT(JSON Web Token)简介
JWT(JSON Web Token) 是一种基于JSON的开放标准(RFC 7519),用于在各方之间作为JSON对象安全地传输信息。它广泛应用于认证和授权机制中,尤其在Web应用、单页应用(SPA)、移动应用和微服务架构中。
JWT的结构
JWT由三部分组成,分别用点(.)分隔:
Header(头部)
Payload(负载)
Signature(签名)
Header
Header包含两部分信息:类型和签名算法。
{
"alg": "HS256",
"typ": "JWT"
}
alg:签名的算法,如HMAC SHA256 (HS256)、RSA (RS256)等。typ:令牌的类型,这里固定为JWT。
- Payload
Payload包含声明(claims),即传输的数据。声明有三类:
- Registered claims(注册声明):预定义的标准声明,如
iss(签发者)、exp(过期时间)、sub(主题)等。 - Public claims(公共声明):可以自由定义,但需要避免冲突,可以使用JWT标准注册的命名空间。
- Private claims(私有声明):自定义的声明,通常用于应用内信息的传输。
示例:
{
"sub": "1234567890",
"name": "John Doe",
"admin": true
}
- Signature
Signature用于验证消息的真实性和数据完整性,防止被篡改。签名的生成步骤:
- 使用Base64Url编码对Header和Payload进行编码。
- 将编码后的Header和Payload用点(.)连接。
- 使用Header中指定的签名算法和密钥对连接后的字符串进行签名。
HMACSHA256(
base64UrlEncode(header) + "." + base64UrlEncode(payload),
secret
)
JWT的工作原理
JWT通常用于认证和授权流程中,典型的使用方式如下:
- 用户登录:
- 用户通过登录接口提交用户名和密码。
- 服务器验证用户凭据,如果正确,生成JWT并返回给客户端。
- 客户端存储JWT:
- 客户端(如浏览器或移动应用)将JWT存储在LocalStorage、SessionStorage或Cookie中。
- 请求受保护资源:
- 客户端在每次请求受保护的资源时,将JWT添加到HTTP头部的
Authorization字段中。 - 服务器接收到请求后,验证JWT的有效性和合法性。
- 如果JWT有效,服务器处理请求并返回响应;否则返回401未授权错误。
- 客户端在每次请求受保护的资源时,将JWT添加到HTTP头部的
示例:
Authorization: Bearer <token>
JWT的优点
- 无状态性:服务器不需要存储会话数据,所有必要的信息都包含在Token中。
- 灵活性:可以在任何编程语言中生成和验证JWT。
- 安全性:通过签名确保Token的真实性和数据完整性。
- 便于扩展:Payload部分可以包含任何类型的声明,便于携带用户信息。
JWT的缺点
- Token过大:由于包含了头部、负载和签名,Token较大,传输和存储开销较高。
- 过期管理:需要妥善管理Token的过期时间和刷新机制,防止长期有效的Token被滥用。
- 不易撤销:一旦签发,Token在有效期内一直有效,除非设计额外的机制来使其失效。
示例代码
以下是一个简单的JWT生成和验证示例,使用Node.js和jsonwebtoken库:
生成JWT:
const jwt = require('jsonwebtoken');
const payload = {
sub: '1234567890',
name: 'John Doe',
admin: true
};
const secret = 'your-256-bit-secret';
const token = jwt.sign(payload, secret, { algorithm: 'HS256', expiresIn: '1h' });
console.log(token);
验证JWT:
const jwt = require('jsonwebtoken');
const token = 'your.jwt.token.here';
const secret = 'your-256-bit-secret';
try {
const decoded = jwt.verify(token, secret);
console.log(decoded);
} catch (err) {
console.error('Invalid token', err);
}
总结
JWT是一种轻量级、无状态的认证机制,广泛用于Web应用和API中。它通过签名保证了数据的完整性和真实性,但也需要妥善管理Token的生命周期和安全性,以确保系统的整体安全。
网络相关的命令
netstat 和 ss 是两个用于查看网络连接信息的命令工具。下面是这两个命令的介绍及常用参数:
netstat 命令
netstat 是一个用于显示网络连接、路由表、接口统计信息、伪装连接以及多播成员的命令行工具。
常用参数:
-a:显示所有连接和监听端口。-t:显示TCP协议的连接。-u:显示UDP协议的连接。-n:以数字形式显示地址和端口号。-p:显示使用网络连接的程序PID和名称(需要root权限)。-l:仅显示监听的套接字。-r:显示路由表。-s:显示每个协议的统计信息。-i:显示网络接口的状态。-c:每隔一段时间重复执行命令。
示例:
netstat -an # 显示所有连接和监听端口,以数字形式表示
netstat -tuln # 显示所有监听的TCP和UDP连接
netstat -p # 显示使用网络连接的程序PID和名称(需要root权限)
netstat -r # 显示路由表
ss 命令
ss 是一个更快、更详细的工具,用于显示网络套接字统计信息。它是 netstat 的替代品。
常用参数:
-t:显示TCP套接字。-u:显示UDP套接字。-l:仅显示监听的套接字。-a:显示所有套接字(包括监听和非监听)。-n:以数字形式显示地址和端口号。-p:显示使用网络连接的程序(需要root权限)。-r:显示路由信息。-s:显示套接字统计信息。-o:显示计时器信息。-k:显示内核TCP套接字(需要root权限)。
示例:
ss -an # 显示所有套接字,以数字形式表示
ss -tuln # 显示所有监听的TCP和UDP连接
ss -p # 显示使用网络连接的程序(需要root权限)
ss -s # 显示套接字统计信息
ss -o state time-wait # 显示处于TIME_WAIT状态的连接
这些命令和参数能够帮助你详细了解系统的网络连接状态,并对网络问题进行排查和诊断。
数据库
MySQL
索引的种类
按照数据结构分类:B+树索引、Hash索引、Full-text索引、有序数组
哈希表
使用key-value存储数据,适用于做等值查找,插入数据的时候无需维护顺序,效率高。
缺点在不适合做区间查找,因为hash表是无序的。
有序数组
等值查询和区间查询性能都很优秀,但是不适合做频繁的增删差改的场景。
等值查询使用二分查找,时间复杂度O(logn);区间查找先使用二分查找找到左边界,然后再向右扫描,直到大于右边界。
二叉搜索树BST, Balence Search Tree
保留了有序数组查询性能好的优点,也解决了“有序数组”不适合增删差改的缺点
查询的时间复杂度:O(logn),维护平衡的时间复杂度:O(logn)
n叉树
通过使用n叉树降低树的高度,从而减少磁盘IO次数,提高效率
按照物理存储分类:聚簇索引(主键索引)、二级索引(辅助索引)
聚簇索引的叶子节点存放的是实际的数据,所有完整的用户记录都存放在聚簇索引的B+树的叶子节点中;
二级索引的B+树叶子节点存放的是主键值;
主键查询:直接在主键索引所在的B+树中查询,直接返回查询到的叶子节点;
二级索引查询:首先现在普通索引所在的B+树中查询,查询到带查询记录的主键,然后回表,执行主键查询。
因为二级索引多了一个回表操作,所以尽量只用主键查询。
优化:覆盖索引:在二级索引的B+树中能直接查询到结果的过程
按照数据字段分类:主键索引、唯一索引、普通索引、前缀索引
主键索引:建立在主键字段上的索引,一张表上最多只有一个主键索引,不允许有空值
唯一索引:建立在UNIQUE字段上的索引,一张表中可以有多个唯一索引,索引列的值必须唯一,但是允许有空值
普通索引:建立在普通字段上的索引
前缀索引:对于字符串类型的索引,索引建立在字符串前几个字符上,而不必以整个字符串为索引,能够有效降低索引的大小,适用于较长列值的情况
按照字段个数分类:单列索引、联合索引
单列索引:建立在单列上的索引,比如主键索引
联合索引:有多个列组合而成的索引,这适用于多列的查询条件
什么是最左匹配原则?
使用联合索引的时候存在最左匹配原则,也就是最左优先的方式进行索引的匹配。
最左匹配原则要求从索引的最左边的列开始,并且不能跳过中间的列。如果查询条件没有按照索引的顺序进行匹配,则索引可能失效。
比如一个索引是(A,B,C),在查询的时候where子句中包含A=…就可以用这个索引啦;包含A=… B=… 也可以用。但是只有B=…就无法使用这个联合索引。
关于范围查询
最左匹配遇到范围查询的时候(age>10这种)就会停止匹配,范围查询的字段可以使用联合索引,但是范围查询的字段后面无法用到联合索引。
为什么是最左而不是最右?
因为MySQL的索引底部是使用B+树,B+树中的结构是从左到右依次有序。
什么是索引下推?
索引下推讲白了就是在有多个条件的时候,在先筛选条件的时候就把条件加上,减少选中的行。
一个例子:select * from emp where ename=‘xxx’ and job=‘xxx’;
在低版本的mysql中,会先取到匹配的ename和所有的job,然后在server层针对job进行一次过滤。
在高版本的mysql中,取ename匹配时,索引下推同时了过滤了job。这样减少了server的操作,
什么是覆盖索引?
覆盖索引是指从索引B+树中直接返回数据,而无需进行回表操作。比如又一个索引是idx_key1_key2(key1,key2),在执行Select key1 from table where key1=‘xxx’;的时候就可以直接从索引树中返回结果。
但是有两种情况是不能使用覆盖索引的:
1.不满足最左匹配原则
2.SQL查询的字段不属于联合索引
锁
乐观锁的CAS(Compare-And-Swap)
CAS(Compare-And-Swap) 是一种无锁的原子操作,用于实现乐观锁机制。它的基本原理是通过比较和交换来实现数据的一致性。
CAS操作步骤:
- 读取内存位置的当前值(V)。
- 比较内存位置的当前值(V)是否等于预期值(E)。
- 如果相等,则将内存位置的值更新为新值(N)。
- 如果不相等,则表示数据已被其他线程修改,操作失败。
伪代码示例:
public class CASExample {
private AtomicInteger value = new AtomicInteger(0);
public void increment() {
int oldValue;
int newValue;
do {
oldValue = value.get();
newValue = oldValue + 1;
} while (!value.compareAndSet(oldValue, newValue));
}
}
在上述示例中,compareAndSet方法通过CAS操作保证了在多线程环境下的原子性和一致性。
CAS的优缺点:
- 优点: 无锁操作,避免了线程阻塞,性能较高。
- 缺点: 可能导致ABA问题,即一个值在被比较前后虽然发生了变化,但最终回到了原值,CAS无法检测到这种情况。为了解决ABA问题,可以引入版本号。
ABA问题的解决: 可以使用AtomicStampedReference类,通过版本号来标记每次更新,从而解决ABA问题。
public class ABAExample {
private AtomicStampedReference<Integer> value = new AtomicStampedReference<>(0, 0);
public void increment() {
int[] stampHolder = new int[1];
int oldValue;
int newValue;
int oldStamp;
do {
oldValue = value.get(stampHolder);
oldStamp = stampHolder[0];
newValue = oldValue + 1;
} while (!value.compareAndSet(oldValue, newValue, oldStamp, oldStamp + 1));
}
}
事务
事务的特性 ACID
atomicity原子性:要么做,要么不做,通过undo log来保证
consistency一致性:确保数据库从一个一致的状态转移到另一个一致的状态
isolation隔离性:多个事务并发的时候,每个事务不能看到其他事务的中间状态,通过MVCC实现
durability持久性:事务一旦被提交,结果都是保留在数据库中的,通过redo log实现
Redis
Redis如何保证缓存和数据库的一致性?
读场景:不会导致缓存的不一致性
写场景:有一个更新数据库和更新/淘汰缓存的顺序
淘汰cache策略:在更新数据的时候,把现有的cache淘汰掉
优点:操作简单,直接把cache淘汰掉就好;
缺点:在淘汰cache之后会有一段时间出现cache miss的状态。
更新cache策略:在更新数据的时候,直接把缓存也更新了
优点:cache的命中率高,不会出现cache miss
缺点:cache的更新可能会比较复杂,比如更新数据库的一个操作之后,cache并不是直接把db中的数据读出来,而是要经过一系列计算之后才能把cache更新。
业界一般选用淘汰cache的策略,更新cache策略的成本太高,每次更新数据库的时候都要更新cache,而且有可能cache的命中率也不是很高。
方案1:先淘汰缓存,再去更新数据库
正常情况:线程A先淘汰了缓存,更新了数据库;线程B在没有找到缓存数据,去数据库中进行查询,再把数据保存到缓存中
异常情况:(同步更新缓存)线程A先淘汰了缓存,还没有更新完成数据库,数据库中仍然是旧的数据,线程B没有找到缓存,去数据库中查询,并将旧数据保存到了缓存中,等到线程A更新完数据库,就出现了缓存不一致的问题,直到该缓存过期。
解决方式:
使用延迟双删(线程A在完成更新数据库之后休眠M秒,再次淘汰缓存),执行流程为:线程A先淘汰缓存,还没有完成更新数据库的时候,若此时有读操作,会把旧数据放到缓存中,导致了缓存不一致的问题。等到线程A完成更新数据库的操作后,休眠M秒(M稍大于从数据库中读数据的N秒)后,再次淘汰缓存。等到下一次读操作的时候,把新数据加载到缓存中。
异步更新缓存:线程A先淘汰了缓存,还没有更新完成数据库,数据库中仍然是旧的数据,线程B没有找到缓存,去数据库中查询,但是不把数据加载到缓存中,等到线程A完成对数据库的更新之后,通过订阅binlog来异步更新缓存,这种情况下不会导致缓存不一致。
方案2:先更新数据库,再淘汰缓存
正常情况:线程A先更新数据库,然后淘汰了缓存;线程B在没有找到缓存数据,去数据库中进行查询,再把数据保存到缓存中
异常情况:线程A先更新了数据库,此时还没有淘汰缓存,线程B读取了缓存的旧数据,出现了缓存不一致的问题。之后线程A删除了缓存,下一次读操作的时候,把数据加载到缓存中去。(这个方案出现缓存不一致的时间较短,数据最终是一致的)
无论是同步/异步更新缓存,都不会导致数据的最终不一致,在更新数据库期间,cache中的旧数据会被读取,可能会有一段时间的数据不一致,但读的效率很好——保证了数据读取的效率,如果业务对一致性要求不是很高,这种方案最合适
如果有一步出现失败的情况的话,可以把失败的加到重试队列中,直至成功。
缓存雪崩、缓存击穿、缓存穿透
缓存雪崩
概念:大量的缓存在同一时间过期。
预防方式:分散缓存的过期时间,可以使用随机数设置过期时间;或者采取永不过期的策略
缓存击穿
概念:缓存中没有,但是数据库中可以查询到的数据。比如某一个缓存过期了,这个数据的查询就会大量直接去访问数据库,加大数据库的负担。
预防方式:使用互斥锁(如分布式锁),或者在查询数据库前检查缓存是否存在,若不存在再去查询数据库
缓存穿透
概念:缓存中不存在的数据,数据库中也没有的数据,导致每次请求都会直接访问数据库。典型的情况就是攻击者构造了大量的不存在的key,导致对数据库的频繁查询。
预防方式:可以使用布隆过滤器等手段过滤掉恶意请求,或者在查询数据库前进行参数的合法性校验。
Redis分布式锁
Redis分布式锁是利用Redis的单线程特性,通过设置和获取键值对来实现分布式锁机制。常用的实现方法包括使用SETNX命令和RedLock算法。
基本实现方法:
获取锁: 使用
SETNX命令(SET if Not eXists)在Redis中设置一个键,并附带一个过期时间。SETNX lock_key unique_value EXPIRE lock_key expire_time如果返回1,则表示成功获取锁。否则,表示锁已经被其他客户端获取。
释放锁: 释放锁时,需要确保释放的是自己持有的锁,可以通过删除键来释放。
DEL lock_keyRedLock算法: RedLock算法是Redis作者提出的一种分布式锁算法,主要步骤如下:
- 在N个Redis实例上尝试获取锁。
- 如果在大多数实例(如N/2+1个)上成功获取锁,则认为获取成功。
- 设置一个过期时间,防止死锁。
- 在锁的有效时间内完成操作后,释放锁。
Redis分布式锁的使用示例(伪代码):
import redis
import time
def acquire_lock(redis_client, lock_key, unique_value, expire_time):
if redis_client.setnx(lock_key, unique_value):
redis_client.expire(lock_key, expire_time)
return True
return False
def release_lock(redis_client, lock_key, unique_value):
if redis_client.get(lock_key) == unique_value:
redis_client.delete(lock_key)
redis_client = redis.StrictRedis(host='localhost', port=6379, db=0)
lock_key = 'my_lock'
unique_value = '12345'
expire_time = 10 # seconds
if acquire_lock(redis_client, lock_key, unique_value, expire_time):
try:
# Perform critical section operations
pass
finally:
release_lock(redis_client, lock_key, unique_value)
else:
print("Failed to acquire lock")
算法
雪花算法(Snowflake Algorithm)
雪花算法是由Twitter开发的一种分布式唯一ID生成算法,旨在生成高效、排序的全局唯一ID。其生成的ID是64位整数,通过时间戳、机器ID和序列号的组合实现唯一性。
雪花算法的结构:
- 1位符号位:始终为0,表示正数。
- 41位时间戳:表示从某个固定时间开始的毫秒数,可以使用约69年。
- 10位机器ID:用于标识生成ID的机器,支持最多1024个节点。
- 12位序列号:用于区分同一毫秒内生成的不同ID,支持每毫秒生成4096个不同ID。
生成ID的过程:
- 获取当前时间戳。
- 获取机器标识。
- 获取序列号(如果同一毫秒内生成多个ID,序列号会自增)。
- 将以上部分拼接生成唯一ID。
UUID(Universally Unique Identifier)
UUID是一种通用的唯一标识符,标准化由RFC 4122定义,长度为128位。UUID有多种版本,最常用的是版本1和版本4。
常见UUID版本:
- UUID v1:基于时间戳和节点(通常是MAC地址),容易暴露生成时间和生成节点的信息。
- UUID v4:基于随机数生成,唯一性依赖于足够大的随机数空间。
雪花算法与UUID的区别
长度和格式:
- 雪花算法生成的是64位整数,长度较短,适合存储在数据库的整型字段中。
- UUID生成的是128位标识符,通常表示为36个字符的字符串(包含连字符)。
唯一性原理:
- 雪花算法依赖时间戳、机器ID和序列号的组合来保证唯一性,时间戳部分保证了生成的ID按时间递增。
- UUID v1基于时间戳和MAC地址,UUID v4基于随机数,依赖足够大的随机数空间来保证唯一性。
有序性:
- 雪花算法生成的ID按时间递增,有利于数据库索引和排序。
- UUID v1有一定的有序性,但UUID v4完全随机,无序。
生成效率:
- 雪花算法在分布式系统中高效生成唯一ID,且生成速度快。
- UUID生成相对较慢,尤其是UUID v4需要高质量的随机数生成。
空间占用:
- 雪花算法生成的64位整数,存储和传输开销较小。
- UUID是128位,表示为字符串时占用更多存储和传输空间。
优劣对比
雪花算法的优点:
- 高效生成:适合高并发环境下快速生成唯一ID。
- 有序性:生成的ID按时间递增,有利于数据库索引和查询性能。
- 占用空间小:64位整数,占用空间和传输开销较小。
雪花算法的缺点:
- 依赖时钟:依赖时间戳,如果时钟回拨可能会导致ID冲突。
- 依赖机器ID配置:需要配置和管理机器ID,避免冲突。
UUID的优点:
- 全局唯一性:128位随机数生成,冲突概率极低。
- 独立性:不依赖特定的机器或时间戳,生成过程简单。
UUID的缺点:
- 无序性:UUID v4完全随机,不适合需要有序ID的场景。
- 占用空间大:128位长度,表示为字符串时占用更多存储和传输空间。
- 生成效率较低:尤其是UUID v4,需要高质量的随机数生成,生成速度较慢。
适用场景
雪花算法:
- 高并发系统:需要快速生成唯一ID的分布式系统。
- 数据库索引:需要有序ID来提高数据库索引和查询性能的场景。
UUID:
- 全局唯一标识:需要生成全局唯一标识且不关心有序性的场景。
- 分布式系统:不依赖特定机器和时间戳,适用于无中心化ID生成的分布式系统。
总结
雪花算法和UUID各有优劣,根据具体应用场景选择合适的唯一ID生成策略。雪花算法适用于高并发、有序性要求高的场景,而UUID适用于需要全局唯一标识且不关心有序性的场景。
操作系统
死锁
在计算机系统中,死锁是指两个或多个进程或线程在互相等待对方释放资源的情况下,陷入了一种无法继续执行的状态。死锁通常发生在多任务操作系统中,当多个进程或线程竞争有限的资源时。处理死锁的方法主要包括以下几种:
- 预防死锁
预防死锁是通过在系统设计阶段采取措施,确保死锁不会发生。常见的方法包括:
资源分配策略:
- 互斥:确保资源不能同时被多个进程使用。
- 占有并等待:要求进程在请求新资源之前释放所有已占有的资源。
- 不可抢占:资源不能被强制从进程中抢占。
- 循环等待:对资源进行排序,要求进程按顺序请求资源,避免循环等待。
资源排序:
- 对所有资源进行全局排序,要求进程按顺序请求资源,避免形成循环等待链。
- 避免死锁
避免死锁是在系统运行时动态地检测资源分配状态,确保不会进入可能导致死锁的状态。常见的方法是使用银行家算法(Banker’s Algorithm)。
- 银行家算法:
- 在每次资源请求时,检查如果满足请求后系统是否仍处于安全状态(即存在一种资源分配顺序,使得所有进程都能完成)。如果处于安全状态,则允许请求;否则,拒绝请求。
- 检测死锁
检测死锁是在系统运行时定期检查是否存在死锁。如果检测到死锁,系统可以采取措施来解除死锁。
资源分配图:
- 使用资源分配图(Resource Allocation Graph)来检测是否存在循环等待,从而判断是否发生死锁。
死锁检测算法:
- 定期运行死锁检测算法,检查系统中是否存在死锁。常见的算法包括等待图(Wait-for Graph)算法。
- 解除死锁
如果检测到死锁,系统可以采取以下措施来解除死锁:
资源抢占:
- 选择一个进程,强制释放其占有的资源,并将其回滚到某个安全状态,然后重新启动该进程。
进程终止:
- 选择一个或多个进程终止,释放其占有的资源。通常选择终止那些代价最小的进程。
资源回滚:
- 将系统状态回滚到某个安全状态,然后重新启动所有相关进程。
- 忽略死锁
在某些情况下,系统可能选择忽略死锁,认为死锁发生的概率很低,或者死锁的代价可以接受。这种方法通常用于对死锁不敏感的系统。
总结
处理死锁的方法包括预防、避免、检测和解除死锁。预防和避免是在系统设计阶段采取的措施,而检测和解除是在系统运行时采取的措施。选择哪种方法取决于系统的具体需求和资源管理策略。
页面置换算法
页面置换算法是操作系统中管理虚拟内存的一项重要技术,当物理内存不够用时,操作系统会将不常用的页面置换到磁盘上,以释放内存空间给需要的进程。以下是一些常见的页面置换算法:
FIFO(First-In-First-Out,先进先出)
- 概念:FIFO算法是最简单的一种页面置换算法。它将最早进入内存的页面最先淘汰。可以用队列来实现,队头存放最早加载的页面,队尾存放最新的页面。
- 优点:实现简单,逻辑清晰。
- 缺点:性能可能不好,不考虑页面的实际使用情况,可能会淘汰经常使用的页面,导致“Belady异常”(页框数增加反而增加缺页次数)。
LRU(Least Recently Used,最近最少使用)
- 概念:LRU算法假设最近使用的页面未来仍然会被频繁访问,最近最少使用的页面可能不再需要。该算法将最近最少使用的页面淘汰。
- 实现方式:
- 用一个链表来存储页面,每次访问页面将其移到链表头,链表尾部的页面是最久未使用的,优先淘汰。
- 或者使用计数器来记录每个页面的最后一次访问时间。
- 优点:比FIFO更智能,考虑到了页面的实际使用频率,性能较好。
- 缺点:实现复杂度较高,维护链表或计数器需要额外的开销。
LFU(Least Frequently Used,最少使用次数)
- 概念:LFU算法基于页面的使用频率来决定淘汰哪个页面。使用频率最低的页面将优先淘汰。
- 实现方式:为每个页面维护一个访问计数器,选择访问次数最少的页面淘汰。
- 优点:可以保留那些频繁使用的页面。
- 缺点:可能会出现某些页面在过去被频繁使用,但近期使用较少,仍然不被淘汰的情况,导致内存占用不合理。
OPT(Optimal,最佳页面置换算法)
- 概念:OPT算法是理论上的最优算法,它通过预知未来访问的情况,选择那些未来最晚被访问的页面进行淘汰。
- 实现方式:选择未来最久不再使用的页面进行置换。
- 优点:在理论上可以达到最小的缺页率。
- 缺点:需要预知未来的页面访问情况,实际系统中无法实现,只能用于评估其他算法的性能。
Clock(时钟置换算法)
- 概念:Clock算法是LRU的近似实现,维护一个环形的页面集合,并用一个指针模拟时钟。每次替换时检查指针指向的页面是否最近使用过,如果没有使用过,则进行淘汰;如果使用过,将其标记为未使用,指针移动到下一个页面。
- 优点:实现比LRU简单,性能较好。
- 缺点:对频繁被访问的页面保护不够严格,性能可能不如LRU。
Second Chance(第二次机会算法)
- 概念:Second Chance算法是对FIFO的改进,它为每个页面增加一个访问位(referenced bit),表示该页面最近是否被访问过。当页面需要被淘汰时,如果该页面的访问位为1,则将访问位清零,并跳过此页面,继续检查下一个页面。
- 优点:相比FIFO更合理,防止频繁访问的页面被淘汰。
- 缺点:仍然存在一定的局限性,尤其是在频繁的页面调度情况下。
NRU(Not Recently Used,最近未使用算法)
- 概念:NRU算法将页面分为四类:未被访问、未被修改,未被访问、被修改,已被访问、未被修改,已被访问、被修改。它优先淘汰那些未被访问且未被修改的页面。
- 优点:简单有效,且相比LRU性能开销较小。
- 缺点:和LRU比起来准确度不够,可能无法准确捕捉页面访问的时间次序。
Aging(老化算法)
- 概念:Aging算法通过周期性地衰减页面的优先级来模拟LRU的行为。每隔一段时间,将每个页面的优先级右移,衰减使用次数较少的页面的优先级。最后优先淘汰优先级最低的页面。
- 优点:实现比LRU更简单,能够近似实现LRU。
- 缺点:仍然有一定的时间开销,尤其在频繁的页面替换中。
总结
每种页面置换算法都有各自的适用场景:
- FIFO 简单适用,但性能不佳。
- LRU 是性能较优的算法,适合大多数情况。
- OPT 是理论上的理想算法,但难以实现。
- Clock 和 Second Chance 是对LRU和FIFO的改进,兼顾了性能和实现复杂度。
在实际系统中,算法的选择通常需要根据应用场景的需求、性能要求和实现复杂度进行权衡。
数据结构
拓扑排序
拓扑排序(Topological Sorting)是一种对有向无环图(DAG, Directed Acyclic Graph)进行排序的算法。拓扑排序的结果是一个线性序列,使得对于图中的每一条有向边 u -> v,节点 u 在序列中都出现在节点 v 之前。换句话说,拓扑排序的结果是一个满足所有依赖关系的顺序。
应用场景
拓扑排序常用于解决以下问题:
- 任务调度:在任务调度中,某些任务必须在其他任务完成之后才能开始。拓扑排序可以帮助确定任务的执行顺序。
- 编译顺序:在编译过程中,某些文件依赖于其他文件的编译结果。拓扑排序可以帮助确定文件的编译顺序。
- 课程安排:在课程安排中,某些课程有先修课程的要求。拓扑排序可以帮助确定课程的学习顺序。
算法步骤
拓扑排序的常见算法步骤如下:
- 计算入度:
- 对于每个节点,计算其入度(即指向该节点的边的数量)。
- 初始化队列:
- 将所有入度为 0 的节点加入一个队列(或栈)中。
- 处理队列:
- 从队列中取出一个节点,将其加入拓扑排序的结果序列中。
- 遍历该节点的所有邻接节点,将其入度减 1。
- 如果某个邻接节点的入度变为 0,则将其加入队列。
- 重复步骤 3:
- 重复上述步骤,直到队列为空。
- 检查结果:
- 如果拓扑排序的结果序列包含所有节点,则拓扑排序成功;否则,图中存在环,无法进行拓扑排序。
系统设计
如何设计一个秒杀系统
设计一个秒杀系统是一个非常具有挑战性的任务,特别是在高并发场景下。秒杀系统需要处理大量用户的并发请求,并确保库存的准确性、避免超卖,同时提供较好的用户体验。以下是一个典型秒杀系统的设计思路:
1. 系统架构设计
秒杀系统的核心是快速响应用户请求并确保系统的高可用性。架构需要充分考虑高并发、库存管理、流量控制和安全性。
- 用户层:用户通过Web端或移动端访问秒杀页面。前端通常会做静态资源优化,提前预加载秒杀页面以减少请求时间。
- 应用层:负载均衡和反向代理(如Nginx)分发用户的请求。应用服务通常会水平扩展,通过多台服务器来分担压力。
- 缓存层:Redis、Memcached等缓存系统用于存储秒杀商品信息、用户请求状态以及限流等逻辑,减少对数据库的压力。
- 数据库层:关系型数据库(如MySQL)存储商品和用户数据。为了优化性能,数据库通常会做水平或垂直拆分,并使用主从复制、分库分表来提高查询效率。
- 消息队列:Kafka、RabbitMQ等消息队列用来解耦高并发请求,异步处理订单创建等操作,确保请求有序处理。
2. 核心功能设计
秒杀系统的主要功能包括商品库存管理、订单生成、用户请求处理和流量控制。
库存管理
- 库存预热:将秒杀商品的库存信息提前加载到缓存中(如Redis),减少对数据库的直接操作。
- 库存扣减:采用原子性操作(如Redis的
decr命令)来保证库存的正确扣减,防止超卖现象。如果库存不足,立即返回秒杀失败。 - 异步扣减库存:请求进入消息队列后,通过后端异步处理实际库存扣减操作,降低应用层的并发压力。
订单生成
- 订单幂等性:确保同一个用户不能重复生成订单,可以通过用户和商品的组合键来唯一标识秒杀订单。
- 限流与排队:使用Redis或分布式锁机制,限制每个用户的秒杀请求次数,并为请求排队处理,避免系统过载。
用户请求处理
- 请求排队:用户在秒杀开始前进入排队状态,系统通过排队机制(如令牌桶算法)限制并发数,依次处理用户请求。
- 请求去重:通过Redis或数据库锁来确保每个用户只能提交一次请求,避免多次提交。
流量控制
- 限流:通过Redis的令牌桶算法或滑动窗口限流算法,对秒杀请求进行限流,确保秒杀服务不会被流量过载。
- 防刷机制:对于恶意刷秒杀的用户,可以通过验证码、用户行为分析等手段进行防刷保护。
3. 优化策略
为了应对高并发流量和提高秒杀系统的响应速度,可以采取以下优化策略:
- 缓存优化:将秒杀商品的详情和库存信息提前加载到Redis中,通过缓存直接响应大部分用户请求,减少数据库压力。
- 静态化页面:秒杀页面可以提前静态化,并通过CDN分发给用户,降低应用服务器的负载。
- 异步操作:订单创建、支付等操作可以通过消息队列异步处理,将用户请求和订单处理解耦,提升系统的吞吐量。
- 热点数据分区:对于秒杀这种热点商品的请求,数据访问集中,可以使用分布式缓存或数据库分片来减小热点商品的数据压力。
4. 防止超卖与并发冲突
- 分布式锁:为防止并发请求下超卖的情况,可以通过Redis实现分布式锁,确保同一商品的库存扣减操作是串行的。
- 乐观锁机制:在数据库层,使用乐观锁(如带版本号的行更新)来确保库存扣减的并发安全。
- 事务机制:在数据库操作中使用事务来保证库存扣减和订单创建的原子性,防止异常情况发生导致的超卖或订单不一致问题。
5. 系统的高可用性与容错性
- 服务熔断与降级:在高并发时,秒杀系统可以通过熔断器(如Hystrix)来保护系统,避免整个系统被拖垮。同时可以设置降级机制,让部分用户得到稍后再试的提示。
- 多级缓存与降级策略:当缓存层压力过大时,可以降级到只展示部分商品的秒杀信息或者部分功能暂时关闭,保证核心功能的可用性。
- 数据恢复机制:秒杀过程中,系统需要能够处理意外情况(如网络延迟、系统宕机),通过重试机制或事务日志进行数据恢复,确保系统数据一致性。
6. 安全性
- 验证码:在秒杀过程中通过人机验证(如验证码)来减少机器人刷单的风险。
- 用户验证:秒杀过程中每个用户必须通过登录验证,确保秒杀活动仅对真实用户开放。
- IP限流:对同一IP的秒杀请求做限流处理,避免同一个IP产生过多请求,影响系统的正常服务。
总结
一个完善的秒杀系统需要通过缓存、限流、排队和分布式锁等多种手段来应对高并发,同时确保系统的高可用性、准确性和响应速度。通过合理的架构设计和功能优化,可以有效提高秒杀系统的处理能力,并且保证良好的用户体验。